


请注意:本文章教程,适用于闪豚速写Pro训练。初次使用,请务必浏览本内容进行学习。
请注意:软件安装时,一定不要安装默认路径C盘,C盘系统有权限问题会导致软件出现异常!
两个模型的区别:
| 标准模型 | Small模型 | |
| 训练时长 | 训练5轮左右就可用(训练越多越好) | 训练30~50轮左右可用(训练越多越好) |
| 训练要求 | GPU显存≥24GB | GPU显存≥6GB |
| 训练速度 | 3090每秒2~4条数据训练 4090每秒5~8条数据训练 | 3090每秒10~15条数据训练 4090每秒20~25条数据训练 |
| 模型超长输出能力 | 支持语料长度3倍生成输出 (例如,原始语料1000字,模型能生成3000字) | 对训练语料原始字数生成超长输出不太好 (例如,原始语料1000字,模型仅能生成1000字) |
| 成品模型大小 | 成品模型大约在6Gb左右 | 成品模型大约在2Gb左右 |
| 知识训练能力 | 能承载百万级以上语料训练 | 仅承载50万级语料以下训练 |
对于模型的训练速度预测,可以使用官网在线计算器,根据你显卡型号的CUDA数量进行训练时间预估计算,在线计算器请点击下方URL链接:
https://www.stunai.cn/mdcalculator
一、软件安装工使用
软件安装使用,需要安装CUDA驱动以及安装CUDNN提供训练加速。具体请参照以下文章教程,点击跳转。请务必按照教程中步骤,进行驱动安装和CUDNN的安装。
(请注意,CUDA驱动是CUDA驱动,显卡驱动是显卡驱动,请不要搞混淆。教程中最下面提供CUDA驱动和CUDNN安装包。自行下载根据教程流程安装。)
二、软件注册激活
1、用户注册
打开软件后,首先点击用户注册按钮,跳转注册页面,按照要求进行资料填写,邀请码可不用填写。注册完成后,会自动跳转“激活”页面,输入激活码进行激活即可使用。
2、软件激活
在激活页面中,需要输入您注册的用户名和密码以及激活卡号。点击激活即可。
(请注意:无需填写充值卡密码)
获得的激活码,一共有三次绑定/两次解绑换绑服务,超出后每次收取500元服务费(仅支持同一IP段换绑,非同IP段换绑则需新购)
三、数据处理
1、数据的准备
闪豚速写Pro训练语料数据要求如下:
每篇学习语料以TXT文件形式保存,文件名推荐使用内容的标题。
格式为:
TXT的第一行为内容的标题
TXT的第二行请保留空行(用作于区分识别作用)
TXT的第三行为内容(内容需要段落分明,尽量不要加载乱七八糟的符号、HTML标签等,少许英文也可以)
可以参考以下图片样例:
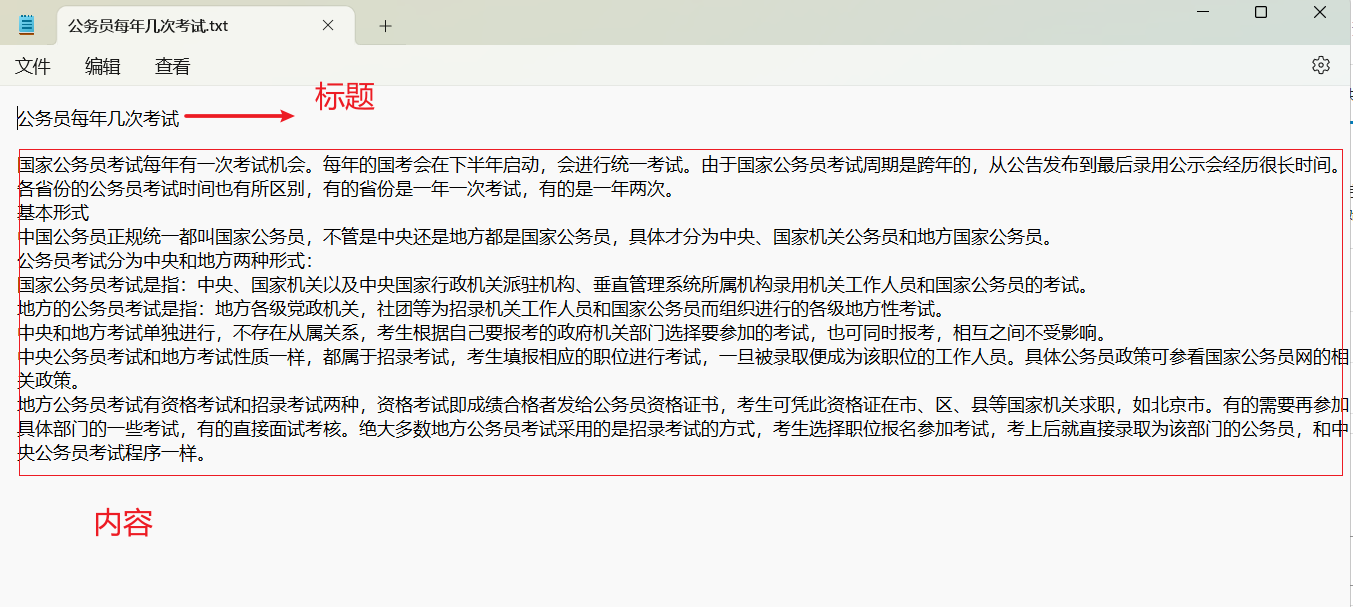
训练语料排版需要段落分明,这样最终学习的模型也会参照语料排版进行学习。
任何模型都很依赖于原始语料,如果您的数据有AI生成数据,那么可能最终的模型也会被检测AI内容,如果对内容检测有要求,请尽量使用22年以前的数据,避免GPT生成的数据进行训练。
训练数据需要5万篇以上,太少的话,模型能力会很弱。
关于语料数量的解释:
1、数据越多,你的模型能力就越强,并不是数据越多,你的模型生成的内容就越多。模型生成的数量是无限的,不管多少数据量训练的模型,同标题生成不同数量的文章内容,都不会重复,仅可能出现少数句子,段落重复。
2、训练语料的多少,决定模型的知识含量而已,增加它的词汇量以及句子理解能力。比如:10万的训练数据,都是小学生学习的词语和句子等内容;20万的语料数据里,就有初中生的学习的内容。不可能模型学习了10万的数据,你让他生成初中的内容,模型是无法生成出来的。因为它都没学习到知识,肯定是不无法生成您所需要的内容。
简单点讲:数据量越多,模型对内容的词汇和知识就掌握的越多。
但推荐模型训练数据在5~50万就可以,不必要上百万。数据量太大,训练时间太长,成本太大,不建议这么操作。
2、工具的使用
训练语料准备好了后,推荐以下工具进行清洗处理:
免费工具:
收费工具:(根据个人需求选择使用)
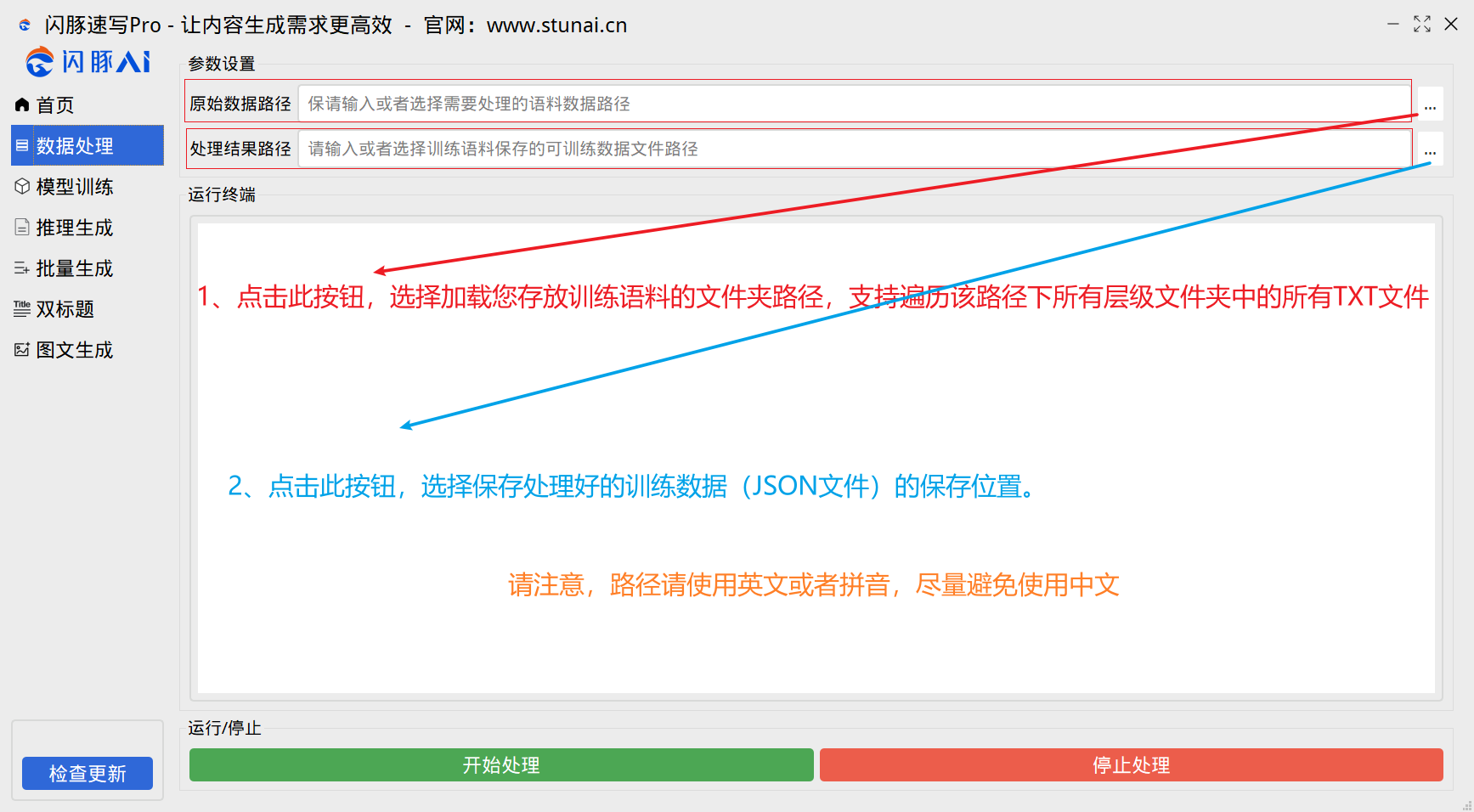
3、训练数据的处理
请参照下图解释说明,填写好对应的路径,点击开始处理即可。
四、模型训练
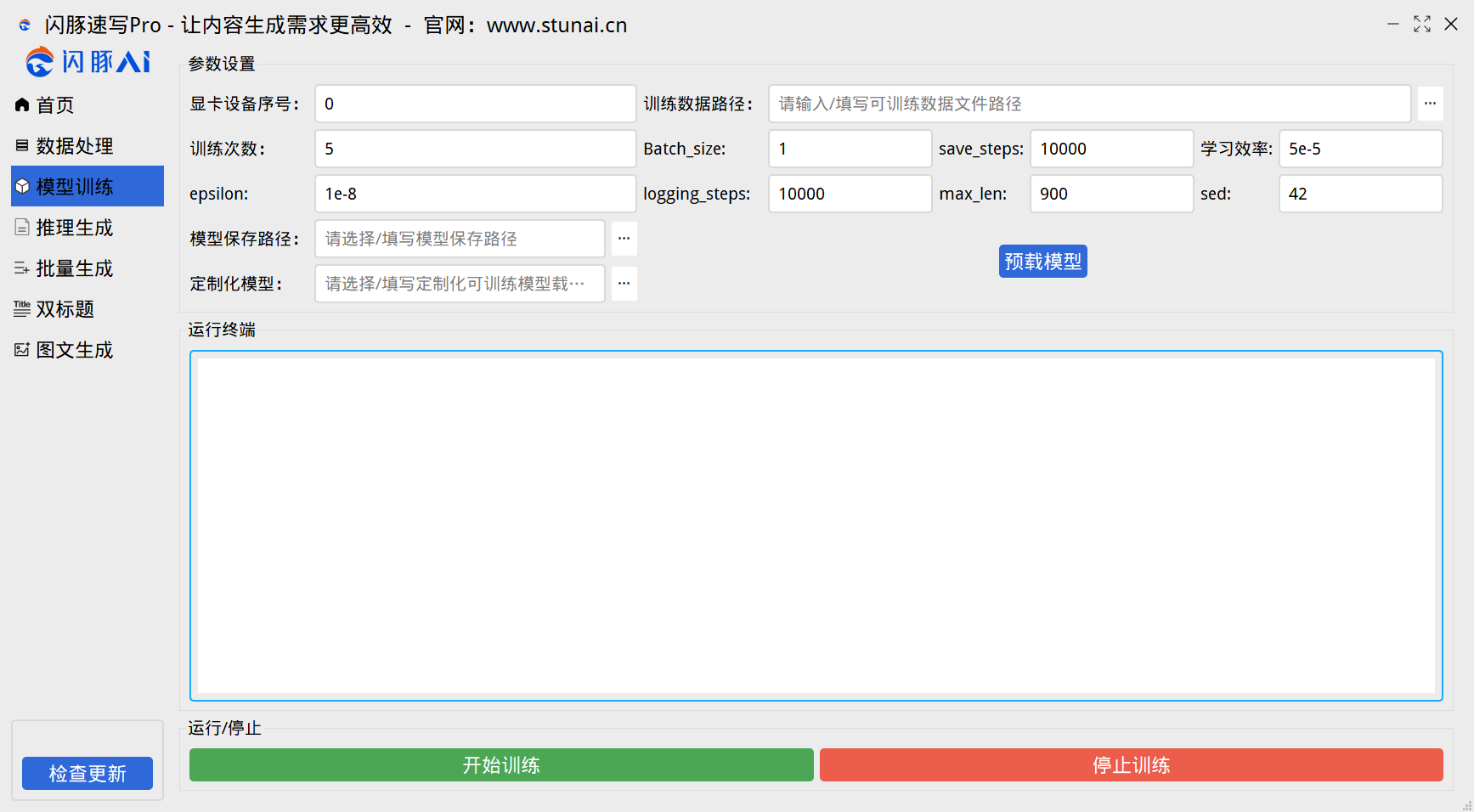
1、参数说明
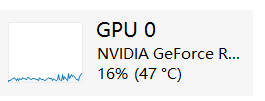
显卡设备序号:默认为0,指的是您显卡在您电脑中的设备序号,基本都是0,无需更改。您可以打开您的电脑任务管理器,在性能里面,有个GPU,GPU后面会有个序号:
训练数据路径:选择您上一步处理的学习语料的文件,也就是JSON文件。
训练次数:对你的数据训练多少次,训练步数=你的数据量。
训练总数=你的语料数据x训练次数。
例如:您的语料数据为10万,那么你的训练步数就是10万步。您设置训练5次,那就是100000x5=50万步。
Batch_size:显卡的批处理,24Gb显存显卡,如果使用标准模型,请保持参数为“1”,如果使用small模型,该参数可以调大,每增加1,占用显存会大一倍。调整此处可以增加模型训练学习效率。
比如:您显存为24Gb,如果使用标准模型,那么仅能设置“1”,如果您使用small模型,该参数可以设置“4”,因为small模型训练占用显存为:“6Gb”左右。
save_steps:该参数为模型保存步数,也就是您训练多少步后保存一个模型,防止模型出错。建议使用默认每一万步就保存一个模型。如果觉得保存太多,占用太多的硬盘空间,那么可以调整该参数,可以设置每5万或者10万或者更多保存一个模型。
学习效率:该参数请保持默认
epsilon:该参数请保持默认
logging_steps:该参数为训练日志的保存,训练日志能直观的看到每条训练数据的学习成果,也就是loss值,一个模型loss值推荐在2以下,就可以很好使用。该参数建议请保持跟save_steps参数保持一致。
max_len:Token词汇量的输入,推荐使用900,参数设置900能更稳定的训练标准模型。如果您使用的是Small小模型,可以使用1024参数。
sed:该参数请保持默认
模型保存路径:该参数请选择训练好的模型保存位置,路径也需要使用英文或者拼音,请避免使用中文路径。
定制化模型:该参数请不要填写,该参数为企业用户私有化定制训练模型的路径。
2、使用流程
根据要求,填写好对应的参数后,请点击预载模型:
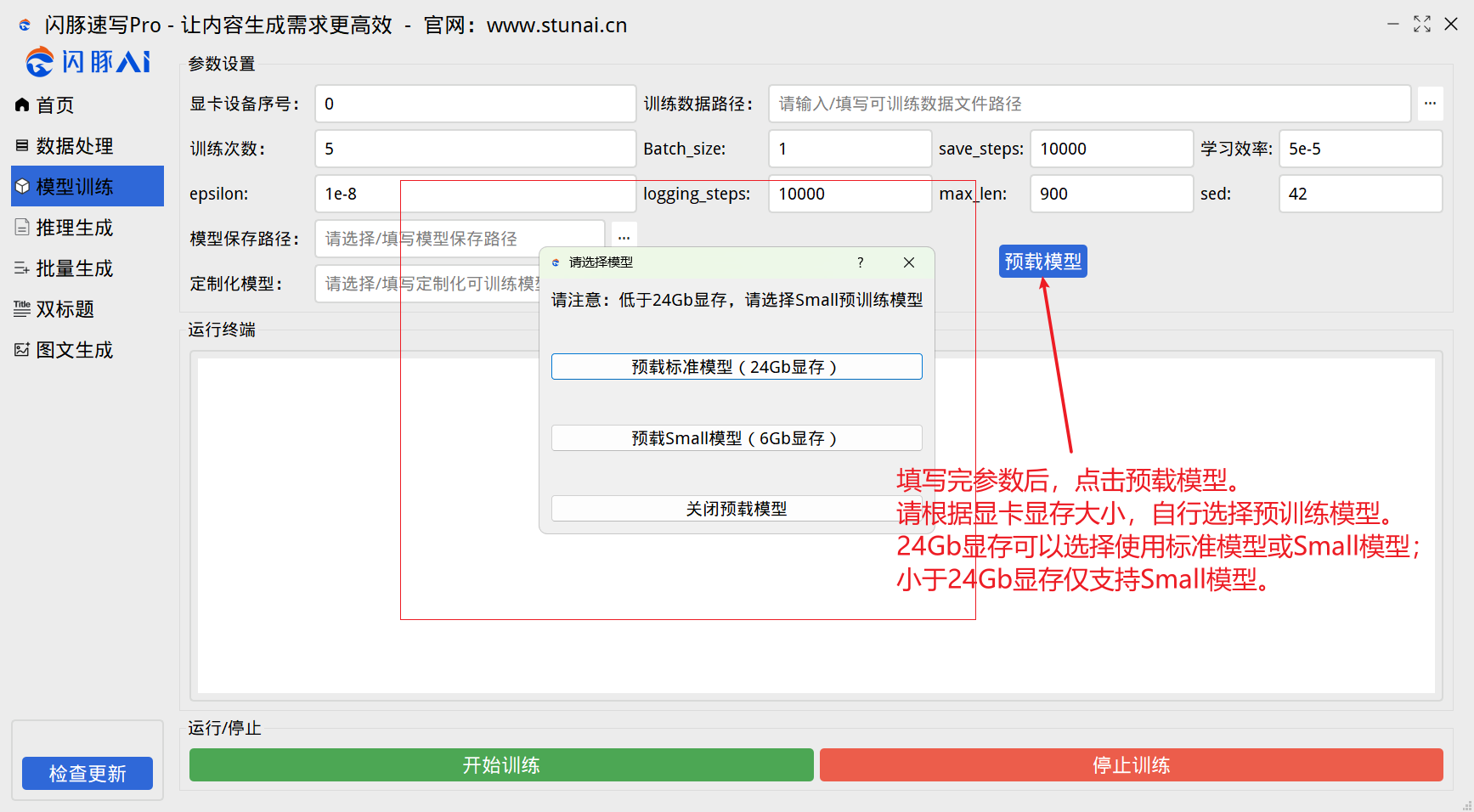
点击后,则会从中央验证服务器中下载加载模型权重:
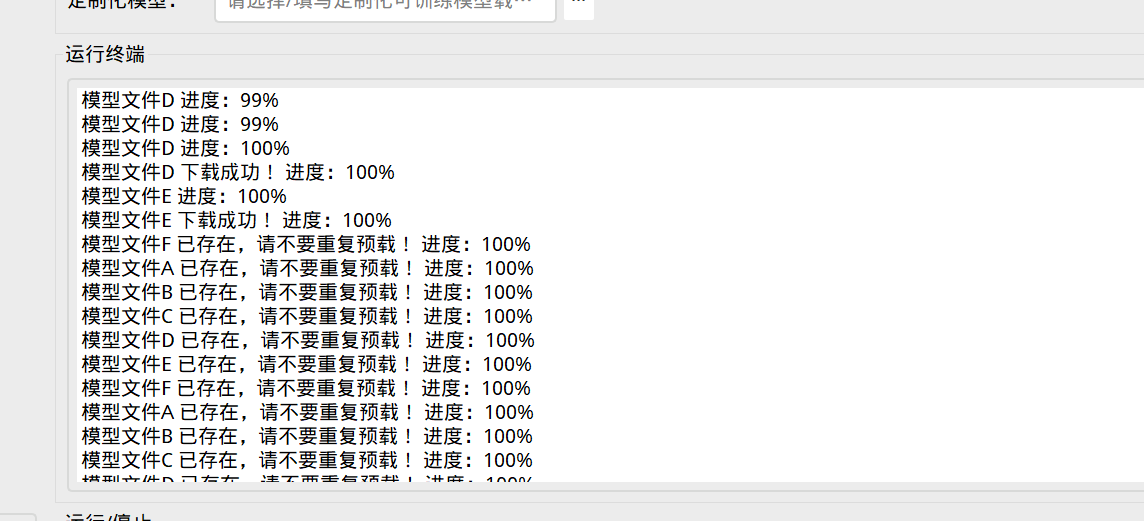
完成后会有以上提醒,模型预载完成后,就可以点击开始训练按钮进行模型训练。
请注意:每次关闭软件后,需要使用模型训练功能,都需要重新点击预载模型。
3、中断训练说明
如果模型训练过程中出现意外导致训练中断,需要接着训练的时候,要确保模型保存路径下至少已保存2份步伐模型;
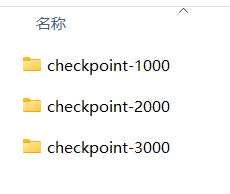
也就是以上图片中的文件夹,请至少确保有2个文件夹以上,才能接着训练。
中断训练会加载倒数第二个文件夹中 的模型权重进行训练。
例如:您的总训练步伐是100万,在您训练26万步的时候,训练中断了,您设置的参数是,每1万步保存一个模型。那么您的路径下应该有:
checkpoint-260000
checkpoint-250000
checkpoint-240000
......
等等模型文件夹。需要继续训练的时候,请保持您上一次的模型训练参数,然后点击预载模型,模型预载完成后,点击开始训练即可。
软件算法会加载您路径下所有的已存储的模型文件夹,自动检索模型权重,最终会从checkpoint-250000开始往后训练。
4、训练其他说明
1、训练完成后,不支持增量训练,仅支持增加训练次数,加深训练。(增量训练是指,您首次训练模型使用的是10万语料,然后第二次训练,重新预处理了20万语料,再训练。这样的话就需要新训练,而不能继续训练,否则导致模型损坏。)
2、训练开始前,可以打开软件的根目录,找到yingpan.ini
打开它。您会看到如下:
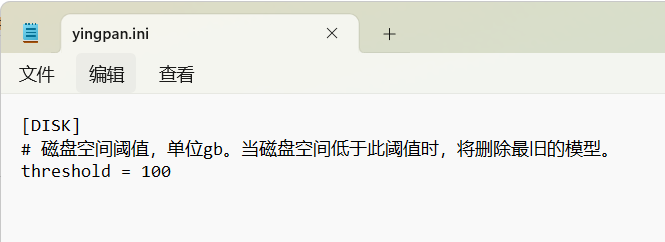
该配置文件主要是给模型训练提供足够的存储空间保障。当您的硬盘空间不足时,达到了软件设置的磁盘空间阈值,软件每次新保存训练模型,则自动删除最老的模型文件,这样循环下去,始终会为您的硬盘保留指定值的空间进行存储新的模型。
如果觉得你硬盘中保存过多的步伐模型保存文件,影响硬盘空间,可以手动删除一些,或者调大保存步伐。手动删除的话,要确保至少预留五个步伐模型,以防止意外。
3、训练过程中,您会看到界面中输出如下值:
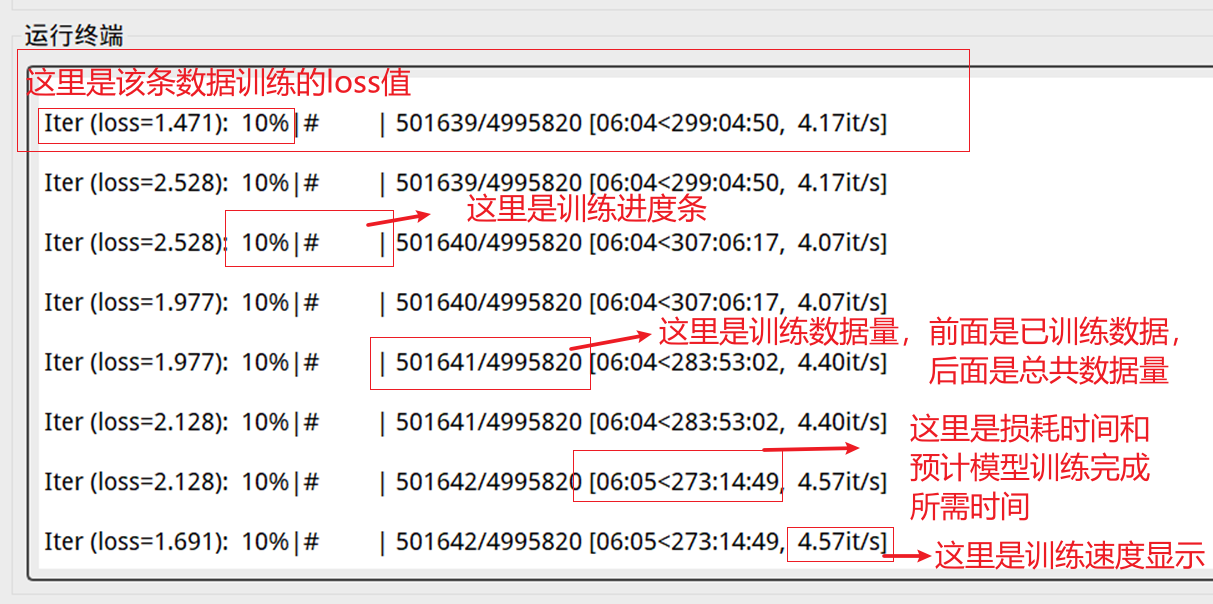
5、模型训练日志
1、首先界面中的:Iter(loss=x.xxx),这个数值仅代表该条训练数据对我们预训练模型的词典进行匹配学习的loss值。仅仅是该条数据的学习值。正确的每批次训练的loss值,在软件的根目录下,logs文件夹内,train-2023-xx-xx-xx-xx.log,该文件内进行查看。该文件名为:train-年-月-日-时-分.log,也就是你开始训练的时间,每次训练,都会有一个开始训练的时间为命名的训练日志。在该日志内查看训练的loss值。
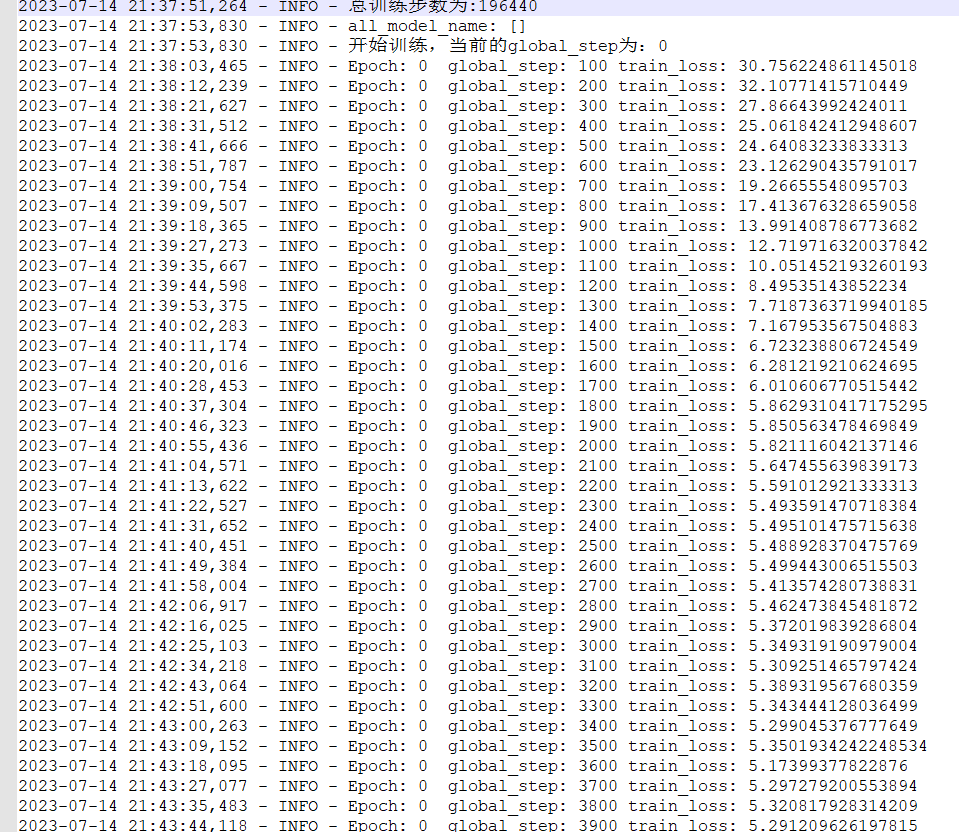
打开日志文件后,日志的记录内容是上图显示;
Epoch代表的是第几轮的训练,从0开始。
global_step:代表的是训练的步数,也就是界面中设置的。
最后看,train_loss值,loss值在2左右,就说明模型基本上学习到了你的数据内容。Loss值越低,模型越好。
五、训练功能其他说明
待补充
六、生成教学
重要说明:载入模型路径,模型文件存储的路径不要有中文!目录路径一定要英文或者拼音!
选择模型路径,是选择你训练好的模型存放的路径,默认模型文件夹名称是:checkpoint-XXXXX(XX代表数字),如:D:/STUNAI/checkpoint-100000
1、批量生成数据表格式要求:
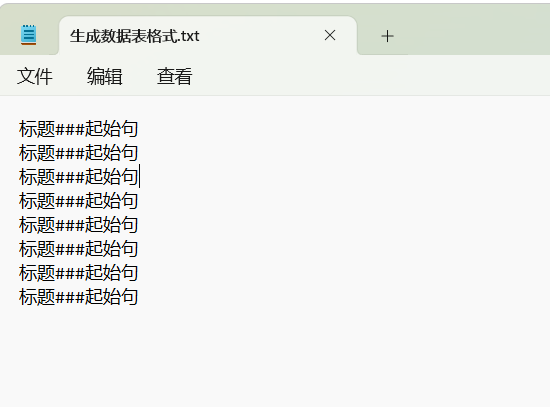
自行创建生成数据,要求格式如上图,新建一份TXT文档,里面生成数据每行一条。
推荐使用官方语料生成数据表提取工具,生成效果会更好。
点击下方卡片推荐内容跳转下载。
如果提取语料的数量比较大,导致数据表很大,建议使用数据表分割工具,进行分割使用。
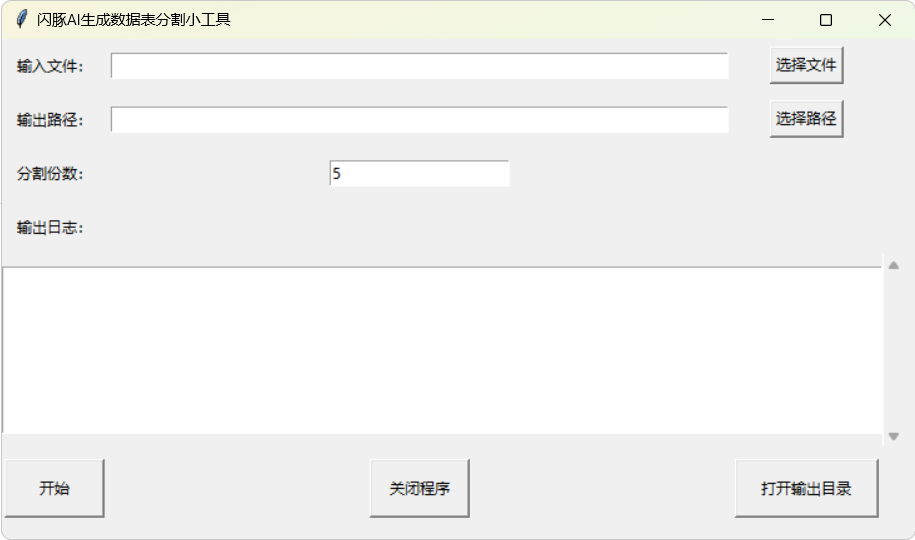
点击下方卡片推荐,进行跳转下载。
提取完成后的数据表标准如下图展示:
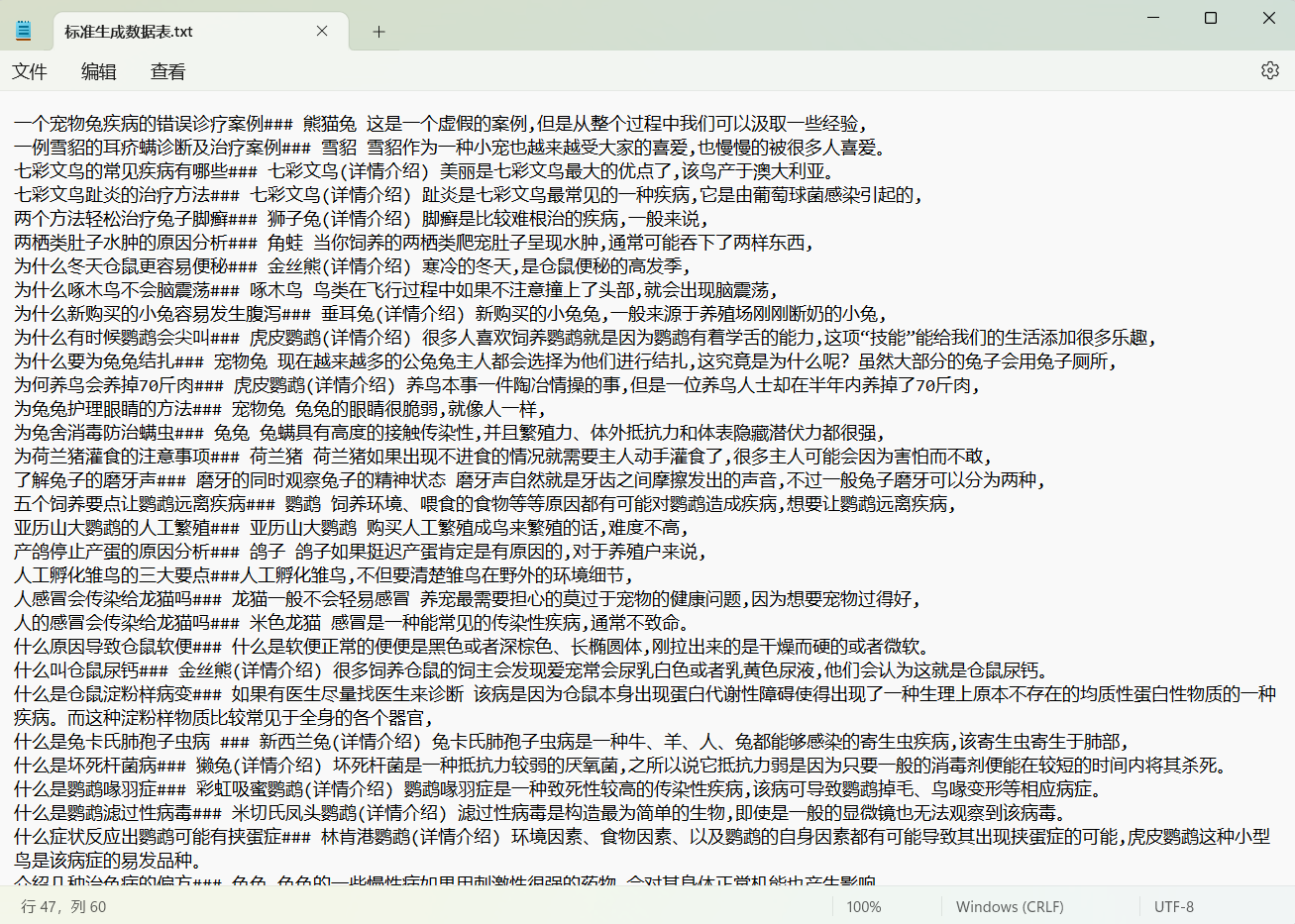
可以看到,标准数据表里面,前面是该条生成任务的标题,###三个井号后面,就是起始句,也就是文章的第一句话。
2、为什么要标题和起始句,直接使用关键词载入生成不行?
对于这个问题,AI模型需要更好的提示,才能推理生成更准确更符合要求的内容。一个关键词仅几个中文字,模型是无法判断你这个任务的最终需求,比如让你自己写一份材料,只有一个关键词,相信你也无法下手写作。AI模型也是一样的道理,需要给它更多的提示和任务指令,它才能更好的输出符合你要求的内容。
AI训练的时候,语料也是有标题和内容的,AI模型学习训练,它需要先学习每篇文章的标题,再学习内容,也就能明白这个标题的作用,所以推理生成的时候,也是一样,需要给它标题和第一句话,引导AI推理更准确的内容。
如果只有关键词,没有标题和起始句怎么办?可以购买根据关键词抓取相关标题和起始句的收费插件。

上面推荐的卡片链接,插件就能实现根据关键词,去爬取相关的标题和起始句。然后会生成标准的生成数据表。
还是更加推荐直接提取语料的标题和起始句,用作生成任务。不用担心,即使同一标题和起始句,最终生成的数据内容,也不会重复一致。
3、提取完数据表后,就可以使用各种批量生成功能
开始生成的时候,建议使用单篇生成,进行模型生成参数调整修改,根据你的模型任务,找到一个最适合的参数,因为软件自带的参数,属于通用参数,中规中矩,用户仔细训练的不同任务的行业模型,都需要调整生成参数,这样才能达到生成效果更好的状态,参数调整教程请点击下方卡片推荐:
调整到了适合的参数后,就去批量生成或者双标题、图文生成中修改你调整的参数,最后就可以进行内容的生产。
4、使用双标题为什么推理会很慢?
因为双标题功能,我们采用的策略是去获取百度下拉结果,需要与百度进行通信,所以就会导致有个时间损耗,会比普通生成慢。如果自己有双标题工具,完全可以使用自己的工具,把数据表的标题,先单独弄成双标题,然后再开启普通的批量生成就行。生成的内容也是聚合生成。
5、图文功能是怎么样的?
软件中,图文生成功能,并不是根据生成内容,生成出图片,而是生成内容的同时,软件算法会根据你需要给内容加入多少张配图,会对内容进行分析,再根据标题,段落内容,去百度图库调取相关图片的URL,最终保存为TXT。(请注意,调用百度图片会有侵权风险,请自行甄别使用)
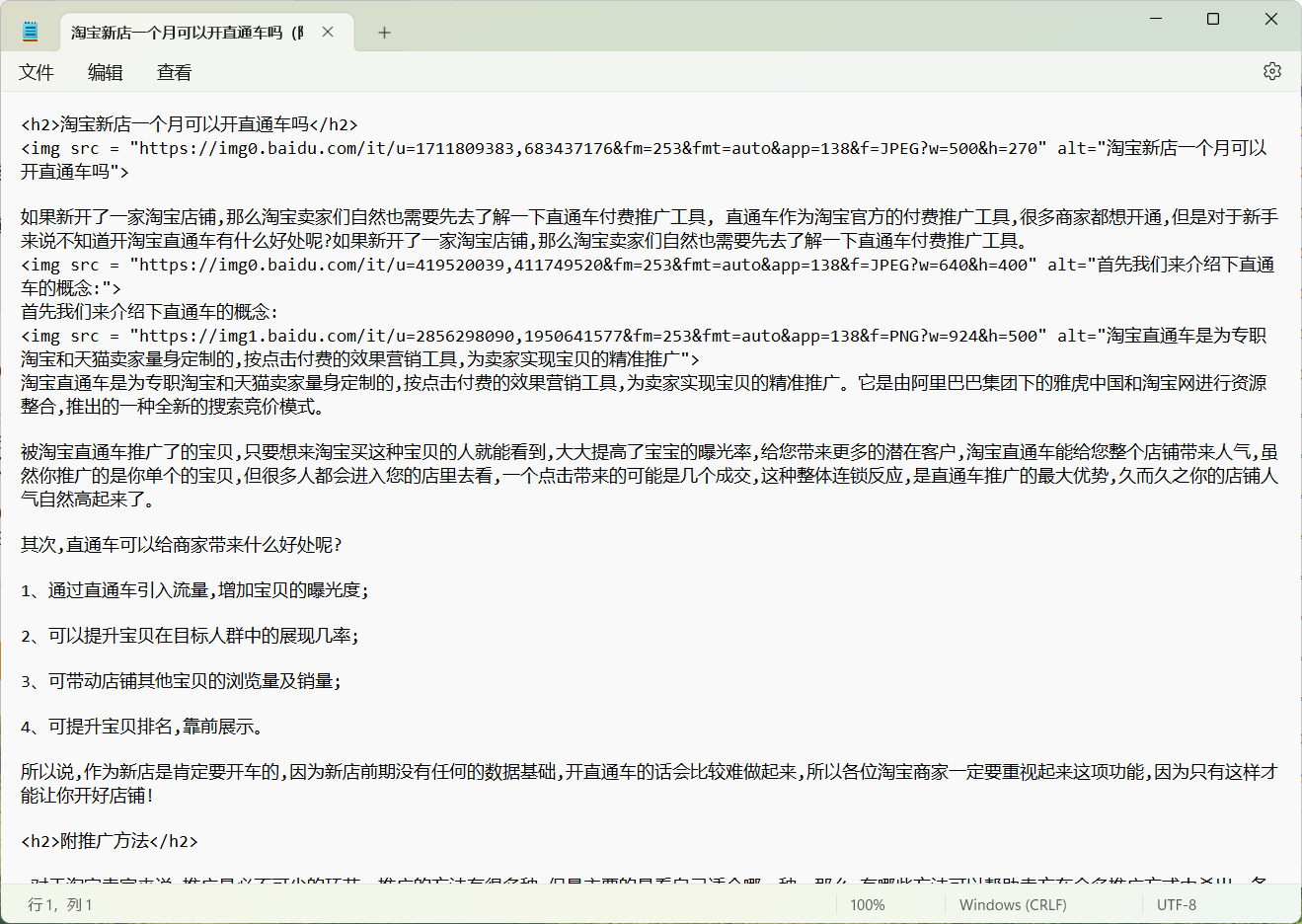
图文生成功能如上图展示,TXT的内容里,穿插<img>URL的标签
6、软件支持标题聚合生成
什么是聚合生成?
当你的标题格式如下:
斑鸠吃什么(斑鸠饲养)###斑鸠吃什么?野外生活的斑鸠一般都是在地面找食,
标题中,斑鸠吃什么(斑鸠饲养)这样的,软件算法则会生成两篇内容,聚合成一篇内容:
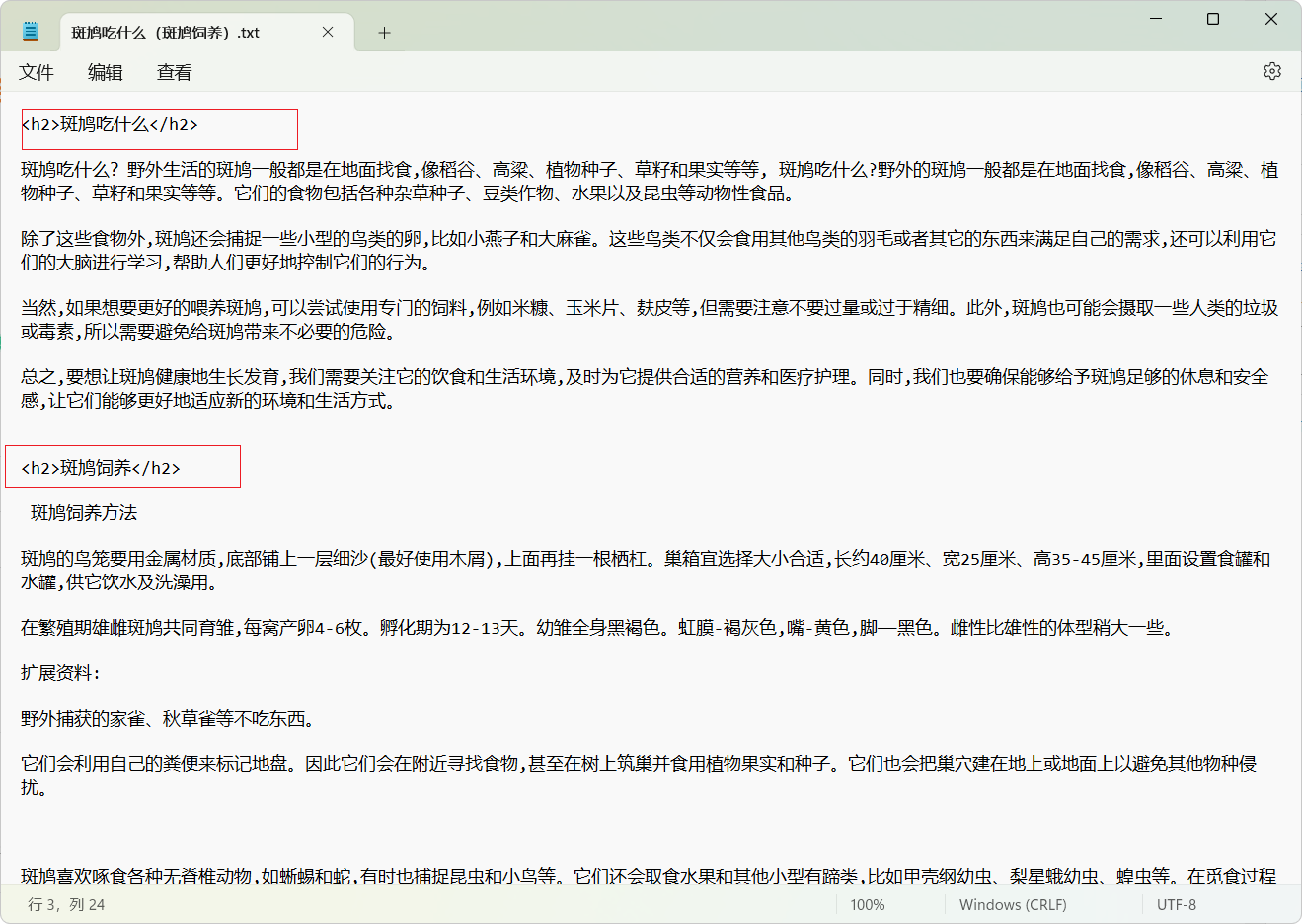
聚合生成支持多种标题格式,如:
标题A(标题B)###起始句
标题A(标题B)###起始句
标题A!标题B###起始句
标题A?标题B###起始句
以上的标题格式,都会进行聚合生成。优先级如下:
()>()>!>?
中文括号(全角括号)>英文括号(半角括号)>感叹号>问号
请注意:如果在括号内的副标题,小于三个中文汉字时候,是不生效的,副标题需要大于三个中文汉字。
所以,在生成数据表中,如果标题含有以上数据格式,都会进行聚合生成,这样就极大避免文章有多标题,但是没有副标题的内容,导致内容关联性不强的问题。
七、其他教学
使用过程中遇到其他问题,先进入教程专区看有没有教程解决,无教程再联系技术售后。
教程专区:https://www.stunai.cn/aidownload/aixuexi
其他问题待补充


怎么联系客服
真的是生成的吗