


注意:不管是训练还是生成,不要把模型放到中文文件夹路径内,路径需要用英文!建议不管是什么数据,路径都选择英文或者拼音,不要用中文!
训练其实跟V3一样的。没什么难度。
语料格式:
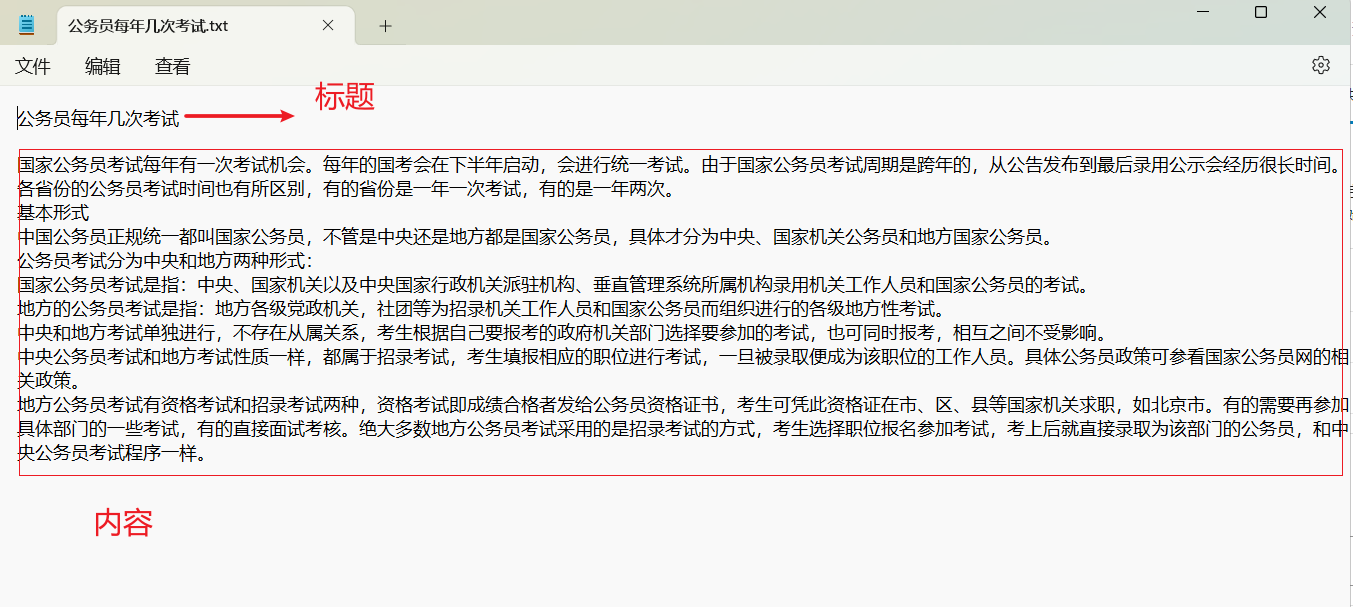
语料格式跟V3要求一样:
每个语料一个TXT文本。
第一行为标题
第二行留空
第三行就是正文内容。(正文内容需要段落分明,不要有夹杂广告等乱七八糟的)
以下就是训练教程:
首先你要准备好你的训练语料,数据在10万左右,肯定是越多越好。现在5万的数据量也能训练,但是需要训练稍微步伐多点就行。
首先打开我们的闪豚速写Pro
进入数据处理功能
选择好你的原始数据路径,选择好保存路径,就可以点击开始处理了。就会生成到你保存路径下有个train_data.json
打开后,数据就是这样的
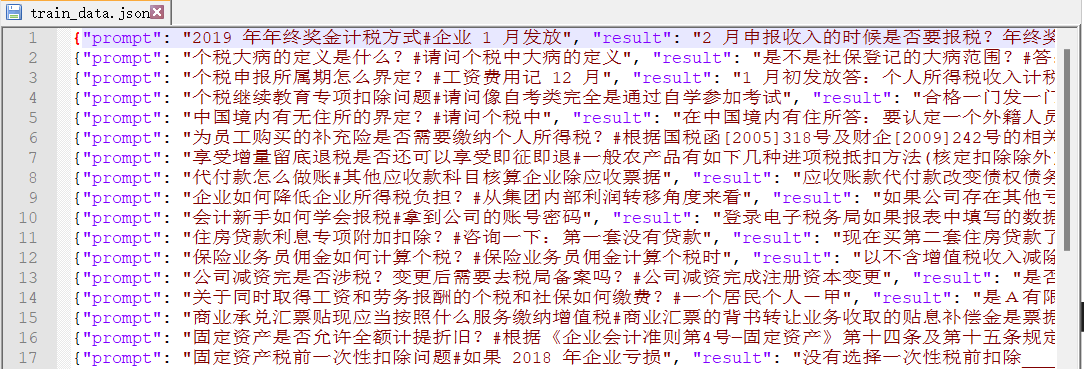
处理完了,就可以进入模型训练的功能了。
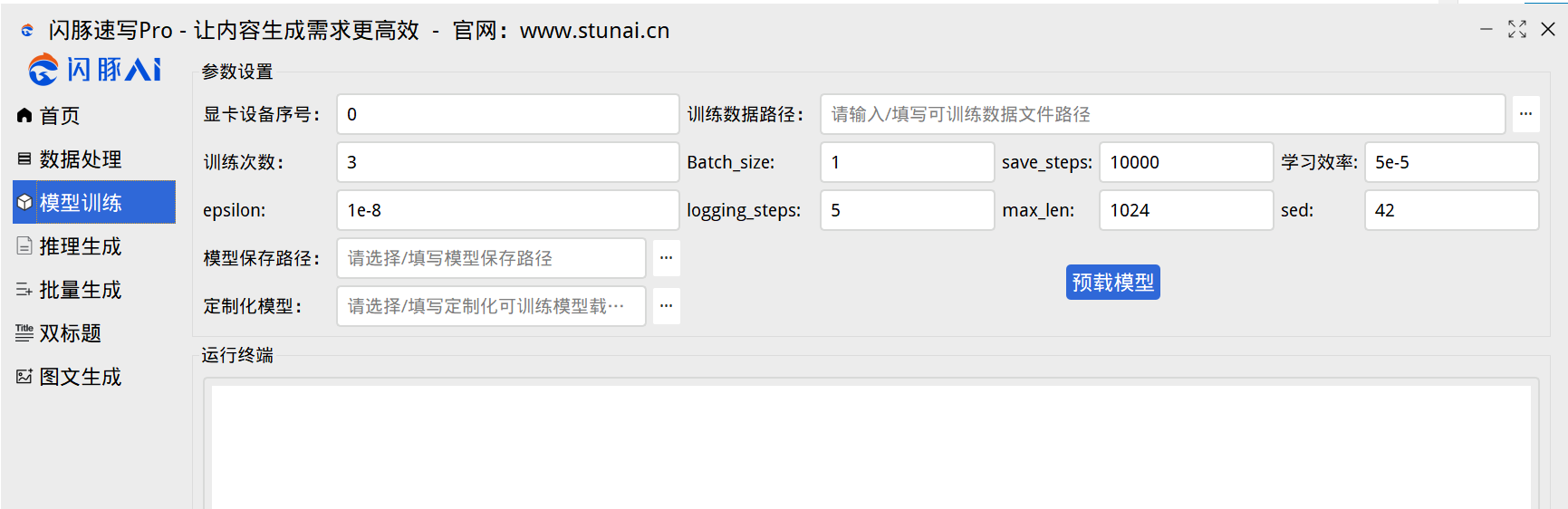
选择好你的训练数据,就是你刚刚处理的JSON这个文件。
显卡设备基本上都是0(基本不用更改)
训练次数:默认也可以,你调多点也可以,当是数据少的时候,就要调多些,什么10轮,20轮。
Batch_size:这个默认1就行。如果你是A100啥的,你这个就调高,1=23Gb的显存。
save_steps:这个默认就可以,但是如果你的数据就几万,你可以调小点,比如:1000,默认是100000,意思就是,每训练10000步,就会先保存一个阶段性的模型。(如果你不想每10000步就保存一个模型,怕占用硬盘空间大,那就把这个值设置大一些,步伐模型保存是根据这个值保存的,设置10万步,则就跑完10条训练数据才保存一个步伐模型)
其他的参数都默认就可以
选择好你的模型保存路径就行。
定制化模型:这个基本上不用选,这个是给大客户定制的一些私有化预训练模型用的。
最后,点击:预载模型(加载预训练模型)
不预载模型的话,是训练不了的,开始训练的时候都需要根据自己的显存预载对应的模型(24Gb显存就预载标准模型,低于24Gb显存的显卡就预载Small模型),预载模型需要从我们验证服务器上下载,时间需要长一些,耐心等待加载完成就行。后面就预载后就很快。
预载完成后就可以点击训练。


挺好的
真的是生成的吗